 お問い合わせ
お問い合わせ
 資料請求
資料請求
目次
アンケート実施後は、データを有効活用するために回答結果の集計・分析・結論付けをします。
本記事では、意思決定に役立つ結果の見方や流れについて、集計・分析手法、Excelでの集計方法についてまとめました。
意思決定に役立つデータにするために本記事をぜひ参考にしてみてください。
本記事では、意思決定に役立つ結果の見方や流れについて、集計・分析手法、Excelでの集計方法についてまとめました。
意思決定に役立つデータにするために本記事をぜひ参考にしてみてください。

アンケートをまとめる際の流れ一覧
アンケートをまとめるまでの流れは以下のような手順となります。
1.アンケートの設計
2.アンケートの作成
3.アンケートの実施
4.アンケートの集計/分析
5.アンケートをまとめる(レポーティング)
1.アンケートの設計
2.アンケートの作成
3.アンケートの実施
4.アンケートの集計/分析
5.アンケートをまとめる(レポーティング)
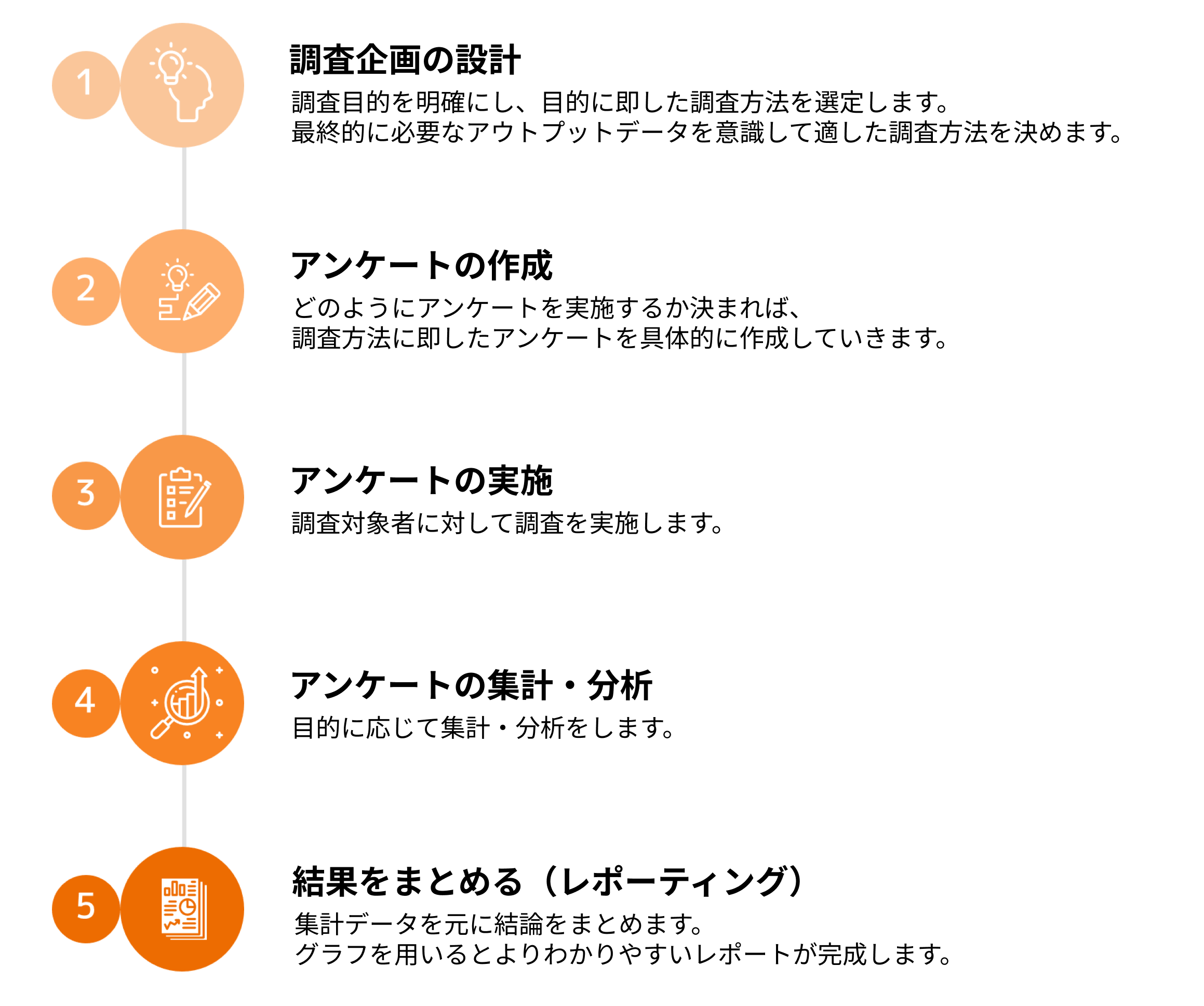
アンケートの結果から次のアクションを起こすために、アンケートで何を聞くべきかの目的を明確にした上で実施することが重要です。
1つ目のステップである「設計」部分で、リサーチの成功可否が90%決まるとも言われております。また、アンケートをどのような形式で行うのかなども設計に含まれますので、内容に併せて最適なツールを用いましょう。
調査の種類については下記の記事で詳細に紹介しております。
市場調査とは?種類と実施方法、事例を紹介
1つ目のステップである「設計」部分で、リサーチの成功可否が90%決まるとも言われております。また、アンケートをどのような形式で行うのかなども設計に含まれますので、内容に併せて最適なツールを用いましょう。
調査の種類については下記の記事で詳細に紹介しております。
市場調査とは?種類と実施方法、事例を紹介
アンケート結果の集計方法
最初に、アンケートで得た結果を集計する方法を解説します。アンケートの集計方法には「単純集計」「クロス集計」「自由記述集計」があり、目的に応じて使い分けます。以下で詳しく解説します。
単純集計
単純集計とは、調査データを集計する際に最も基本的な方法です。回答の総数や割合を集計します。各回答項目ごとの頻度や割合を示すために使用され、データの概要を把握するのに役立ちます。

クロス集計
クロス集計とは、2つ以上の変数を掛け合わせて分析する集計方法です。単純集計で全体の傾向を把握したあとに、各変数を組み合わせデータを詳細に確認します。属性や他設問との掛け合わせでより深堀した傾向まで把握できると次の課題が見えやすくなります。

自由記述集計
自由記述とは複数の選択肢から答えを選ぶのではなく、意見や感想を自由に記述する回答方式です。自由記述を集計するには、回答が数値であれば単純集計やクロス集計でデータ化できるものの、文章の場合はばらつきが多いためアフターコーディングやテキストマイニングによりグループ化します。
アフターコーディングは共通する回答をまとめる方法で、テキストマイニングは頻出単語や文節をまとめる手段です。目的や用途に応じて適した方法を選択しましょう。
アフターコーディングは共通する回答をまとめる方法で、テキストマイニングは頻出単語や文節をまとめる手段です。目的や用途に応じて適した方法を選択しましょう。
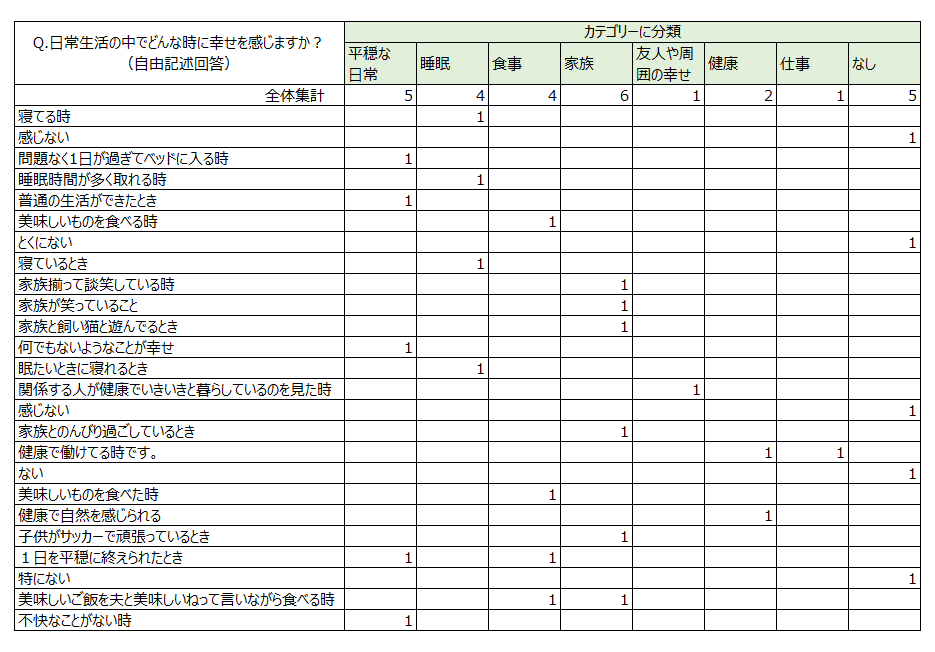

エクセルを用いたアンケート結果のまとめ方
エクセルでは主にCOUNTIF関数やSUM関数などの関数を用いると、アンケートの結果を集計することが可能です。また、ピボットテーブルを使うことでより詳細な集計が出来ることもポイントです。
具体的なまとめ方については、下記記事で解説しているので併せてご覧ください。
「アンケート結果の集計方法からExcelでのグラフの作り方、効果的な分析方法を紹介」
具体的なまとめ方については、下記記事で解説しているので併せてご覧ください。
「アンケート結果の集計方法からExcelでのグラフの作り方、効果的な分析方法を紹介」
エクセルを用いた集計方法のメリット・デメリット
エクセルを用いた集計方法のメリットは、導入する際の費用を安くできることです。データベース管理システムを利用する場合は何十万円もかかりますが、エクセルであれば高くても数万円です。また操作が簡単であり、列の追加や加工操作、グラフの作成も特別な手順は必要なくクリックや打ち込みだけで終えられます。一方でデメリットとしては、データの統合に膨大な工数がかかります。複数人が同時に編集するのは不向きであり、ラグが起きたり操作によってはデータが破損したりする可能性もあります。また複数な関数が挿入されていると原因を探ったり編集したりするのも時間と手間がかかるでしょう。

ワードを用いたアンケート結果のまとめ方
ワードを用いてアンケート結果をまとめる場合、まずは冒頭に説明文を入れてください。アンケートの目的や用途を説明すると回答者に意図を理解してもらえます。その後、回答者に分かりやすく理解してもらうため表やチェックボックス、またグラフや表を機軸にしてコメントを付けられるように作成してください。その後、グラフや表のコメント欄と回答を元にして内容を分析し、仮説なども立てると結果に応じてまとめやすくなるでしょう。
ワードを用いた集計方法のメリット・デメリット
ワードを用いて集計するメリットは、データを貼り付けできる点です。ワードは表や画像を貼り付けできるため、すでに算出されたデータを元に貼り付けしていけば、データごとに数字を分析できます。ワード自体に表作成の機能も備わっており、サイズのコントロールもしやすいので直感的な作成が可能です。デメリットは、表の行や列を追加するのが面倒なので、細かい部分で分けたい場合や表計算などを重視する際は、エクセルを使用するのがおすすめです。

パワーポイントを用いたアンケート結果のまとめ方
パワーポイントを利用して、アンケートをまとめたい場合は、アンケート結果を集計してグラフや表にまとめます。その後スライドのレイアウトを決定してグラフや表の位置を決定し、デザインとスライドの作成をしてください。スライドを確認して表やグラフなどが正しく表示されているなら、アンケート結果をプレゼンなどで活用できます。
パワーポイントを用いた集計方法のメリット・デメリット
パワーポイントのメリットはグラフやチャートを利用して、データを視覚的に確認できることです。傾向や関係性を一目で把握することが可能であり、スライドを活用して整理もできるため、プレゼンなどで発表する際にわかりやすく組み立てることが可能です。デメリットは集計に関する機能が限定的であり、データの入力が手間になるケースもあり、エクセルと比べると煩雑になるため時間がかかったり、上手くまとめられなかったりする場合もあります。

アンケート結果のまとめ方の手順
アンケート結果はまとめ方によって効果的に活用できるかどうかが変わってきますので、集計・分析の際に気を付けることを解説していきます。アンケート結果のまとめ方は、アンケートの種類を問わず基本的な流れは変わらないのでこれから挙げる5つのポイントを押さえてスムーズに進めましょう。
アンケートを作成する
アンケートを作成するには、事前に必ず目的や用途を決めておきましょう。アンケートはその目的・用途に沿って作っていきます。またどのような調査方法で行うかも、この段階で決めておきましょう。
一般的な定量調査をWebアンケートで行う場合のアンケート票の作成では、質問文や選択肢はわかりやすく誤解を招かないような表現を心がけ、回答を誘導するような文章は避けましょう。回答者の負担を考えると、質問文は10問程度、選択肢は多くて15個程度が望ましいといえます。
また回答方式には、「シングルアンサー」や「マルチアンサー」、「フリーアンサー」、「順位回答」、あてはまる・あてはまらないなどを選ぶ「スケール」、「マトリクス」など、さまざまな方法があります。質問の意図に合致していて回答者が答えやすく、かつ後の集計が容易にできる方法を選びましょう。
アンケート作成から集計まで直感的に操作できる│サーベロイドの機能を確認する
一般的な定量調査をWebアンケートで行う場合のアンケート票の作成では、質問文や選択肢はわかりやすく誤解を招かないような表現を心がけ、回答を誘導するような文章は避けましょう。回答者の負担を考えると、質問文は10問程度、選択肢は多くて15個程度が望ましいといえます。
また回答方式には、「シングルアンサー」や「マルチアンサー」、「フリーアンサー」、「順位回答」、あてはまる・あてはまらないなどを選ぶ「スケール」、「マトリクス」など、さまざまな方法があります。質問の意図に合致していて回答者が答えやすく、かつ後の集計が容易にできる方法を選びましょう。
アンケート作成から集計まで直感的に操作できる│サーベロイドの機能を確認する
アンケートによる調査を実施する
アンケートができたら、実際に調査を行います。
調査方法には、以下のようにオンライン・オフラインで行う方法があり、定量・定性のどちらを行うかによっても選択肢が変わります。調査の目的や用途、予算、調査したい対象者などによって適切な手法を選びましょう。また調査方法によって集計やデータ化の手法が異なるため、この後の集計や分析、まとめ方なども考慮して実施方法を検討するとよいでしょう。
【オンライン調査】
・Web調査
・セルフ型ネットリサーチツール、アプリ
・SNSリサーチ
・オンライングループインタビュー など
【オフライン調査】
・紙媒体によるアンケート
・訪問調査
・郵送調査
・電話調査
・街頭調査
・CLT
・HUT
・行動観察調査
・覆面調査 など
アンケートの作成方法に関しては、以下の記事でも詳しく説明していますので参考にしてください。
アンケートの作り方|実施方法や回答率アップのコツも解説
アンケート調査とは?種類や手法、進め方、注意点を解説
調査方法には、以下のようにオンライン・オフラインで行う方法があり、定量・定性のどちらを行うかによっても選択肢が変わります。調査の目的や用途、予算、調査したい対象者などによって適切な手法を選びましょう。また調査方法によって集計やデータ化の手法が異なるため、この後の集計や分析、まとめ方なども考慮して実施方法を検討するとよいでしょう。
【オンライン調査】
・Web調査
・セルフ型ネットリサーチツール、アプリ
・SNSリサーチ
・オンライングループインタビュー など
【オフライン調査】
・紙媒体によるアンケート
・訪問調査
・郵送調査
・電話調査
・街頭調査
・CLT
・HUT
・行動観察調査
・覆面調査 など
アンケートの作成方法に関しては、以下の記事でも詳しく説明していますので参考にしてください。
アンケートの作り方|実施方法や回答率アップのコツも解説
アンケート調査とは?種類や手法、進め方、注意点を解説
-
オンラインでスピーディーに調査する調査ツールの詳細を確認する
-
1万円からネットリサーチが可能サーベロイドに登録してみる
アンケート結果の集計をする
アンケートデータが回収できたら、結果が見易くなるように集計をします。集計方法は主に2種類あり、質問ごとにどれくらいの人が回答したのか単純に件数だけを数える単純集計がベーシックなものとなり、全体的な回答傾向を確認できます。単純集計だけでも調査結果の把握はできますが、回答者の属性(性別・年齢・居住地等)ごとの詳細データを確認したいときは、クロス集計を活用します。2つの集計結果からデータを把握しましょう。
全体像を把握する
回答結果の集計が終わったら、早速集計データを確認していきます。データの確認手順としては、まず初めに単純集計データから見ることがポイントとなります。
最初から細かい部分を見てしまうと、誤ったデータの解釈をしてしまう可能性があるからです。
また、全体の回答傾向を把握した後に詳細の傾向を確認することで、違和感のある数値(全体から離れた異常値)が目につきやすくなります。このような数値は次につながるアクションに繋がる可能性がありますので、まずは全体像の把握からしましょう。
最初から細かい部分を見てしまうと、誤ったデータの解釈をしてしまう可能性があるからです。
また、全体の回答傾向を把握した後に詳細の傾向を確認することで、違和感のある数値(全体から離れた異常値)が目につきやすくなります。このような数値は次につながるアクションに繋がる可能性がありますので、まずは全体像の把握からしましょう。
細部の確認をする
単純集計結果から全体像の把握をしたら、クロス集計をして詳細データの確認をしましょう。深掘りしたデータを見ることで、より回答者の実態を把握することができます。
例えば自社製品の満足度調査をしたときに、全体の満足度が60%だったとします。もう少し満足度を上げたいところです。そこで満足していると回答した人を性別ごとに確認すると、女性80%、男性20%だったことがわかりました。このことから、男性の満足度を上げることで全体の満足度の底上げができると判断することができます。
このように性別ごとの回答結果を見た時に男女差が出れば男性にフォーカスした施策を実施するなど、その後のマーケティング活動に影響を与えるでしょう。
例えば自社製品の満足度調査をしたときに、全体の満足度が60%だったとします。もう少し満足度を上げたいところです。そこで満足していると回答した人を性別ごとに確認すると、女性80%、男性20%だったことがわかりました。このことから、男性の満足度を上げることで全体の満足度の底上げができると判断することができます。
このように性別ごとの回答結果を見た時に男女差が出れば男性にフォーカスした施策を実施するなど、その後のマーケティング活動に影響を与えるでしょう。
データの信憑性を確認する
アンケートで収集したデータは信憑性がある(有意である)ことが前提です。
信憑性がないデータとは、回答数が少ない、回答者の代表性に欠ける(何らかのバイアスがかかっている)などが挙げられ、偏りが大きなものを指します。そのためこのようなデータは、参考値として扱う程度にとどめておいた方が良いです。
例えば男女比が6:4の大学(母集団2000人)があり、2000人全てにアンケートをとることが難しいためランダムで学生400人にアンケートを取ったときに、データの回収結果が3:7の男女比になっていると、本来の構成比からずれているため、代表性に欠けるということになります。
▼関連記事
アンケートの回収サンプル数の決め方について信頼できるデータ数は?
信憑性がないデータとは、回答数が少ない、回答者の代表性に欠ける(何らかのバイアスがかかっている)などが挙げられ、偏りが大きなものを指します。そのためこのようなデータは、参考値として扱う程度にとどめておいた方が良いです。
例えば男女比が6:4の大学(母集団2000人)があり、2000人全てにアンケートをとることが難しいためランダムで学生400人にアンケートを取ったときに、データの回収結果が3:7の男女比になっていると、本来の構成比からずれているため、代表性に欠けるということになります。
▼関連記事
アンケートの回収サンプル数の決め方について信頼できるデータ数は?
結論を導き出す
有意なデータを用いて分析まで終わったら、アンケートを実施した目的に立ち返り結論を導き出します。
結論を出す際に注意したいことは、「因果関係」と「相関関係」を取り違えてしまわないことです。
どちらも調査をしていると聞いたことがある単語だと思いますが、似たようなイメージがあり混合しやすいと思います。
因果関係…原因とそれによって生ずる結果との関係(Aを原因としてBが変動すること)
相関関係…一方が他方との関係を離れては意味をなさないようなものの間の関係(Aが変化するとBも変化する)
例を用いて2つの違いについて解説します。
Aさんがある地域の自動販売機の数と犯罪件数を調べたところ、2つのデータに正の相関関係があることがわかりました。つまり、自動販売機が多い地域ほど犯罪件数が多いということです。
しかしこのデータから「犯罪を減らすために自動販売機の数も減らそう!」と提案すると、まったがかかります。
確かに相関関係はあるとは言えますが、自動販売機と犯罪の間には直接的な因果関係はありません。すなわち、相関関係があるからといって、因果関係もあると主張することは簡単ではないのです。別問題ということを念頭に置いておきましょう。
結論を出す際に注意したいことは、「因果関係」と「相関関係」を取り違えてしまわないことです。
どちらも調査をしていると聞いたことがある単語だと思いますが、似たようなイメージがあり混合しやすいと思います。
因果関係…原因とそれによって生ずる結果との関係(Aを原因としてBが変動すること)
相関関係…一方が他方との関係を離れては意味をなさないようなものの間の関係(Aが変化するとBも変化する)
例を用いて2つの違いについて解説します。
Aさんがある地域の自動販売機の数と犯罪件数を調べたところ、2つのデータに正の相関関係があることがわかりました。つまり、自動販売機が多い地域ほど犯罪件数が多いということです。
しかしこのデータから「犯罪を減らすために自動販売機の数も減らそう!」と提案すると、まったがかかります。
確かに相関関係はあるとは言えますが、自動販売機と犯罪の間には直接的な因果関係はありません。すなわち、相関関係があるからといって、因果関係もあると主張することは簡単ではないのです。別問題ということを念頭に置いておきましょう。
-
アンケート作成から集計まで出来る!サーベロイドの詳細を見る
-
スピーディーに仮説検証が出来る!サーベロイドに登録してみる

アンケート結果の分析方法
代表的な分析方法について4つご紹介します。それぞれ調査の目的に応じてアプローチする分析手法が変わってきますので、どんな調査によく使われるのか特徴も交えながら解説します。
意思決定に関わる大事なフェーズなだけにどのような手法でどんな結果を得たいかは慎重に判断しましょう。
意思決定に関わる大事なフェーズなだけにどのような手法でどんな結果を得たいかは慎重に判断しましょう。
クラスター分析
異なる性質のものが混ざり合ったデータの中から、互いに似たものを集めて集団(クラスター)を作り、対象を分類する方法です。対象は人だけでなく商品や企業等にも及びますが、分類することによってブランドのポジショニング確認や、生活者のセグメンテーション等を知ることができます。
アソシエーション分析
ある商品と同時に購入されている商品の傾向を見つけ出す分析手法です。実店舗とネットショップでの買い物の仕方の違いや最適な商品配置を導き出すこともできます。
「○○を買うと△△も一緒に買う」というパターンや関連性を数字で知ることができるので、セールスにおける戦略を考える時に有効な分析手法です。購買データの分析結果から思わぬところに関連性が見つかると、新たなアプローチを見つけることができるでしょう。
「○○を買うと△△も一緒に買う」というパターンや関連性を数字で知ることができるので、セールスにおける戦略を考える時に有効な分析手法です。購買データの分析結果から思わぬところに関連性が見つかると、新たなアプローチを見つけることができるでしょう。
主成分分析
たくさんある変数を少数の変数に集約する分析手法です。情報を集約することでデータ全体が可視化され解釈しやすくなります。
元データの情報をなるべく失わずにいくつかの変数に集約することがポイントとなり、主成分が元のデータの何割を説明できているのかは寄与率を算出することで確認することができます。寄与率は80%程の主成分軸(変数)で設定すると良いと言われています。
元データの情報をなるべく失わずにいくつかの変数に集約することがポイントとなり、主成分が元のデータの何割を説明できているのかは寄与率を算出することで確認することができます。寄与率は80%程の主成分軸(変数)で設定すると良いと言われています。
決定木分析
決定木分析とは、樹木状にデータを分類していく手法で、目的変数に最も影響する説明変数を導き出します。予測モデルの分析や現状のデータ構造を把握に使われ、比較的に使い勝手が良い手法と言われています。
目的変数に一番効いている説明変数を見つけるときに、決定木分析を用いると1つ1つクロス集計で確認することなく、簡単に可視化することができます。
目的変数に一番効いている説明変数を見つけるときに、決定木分析を用いると1つ1つクロス集計で確認することなく、簡単に可視化することができます。
時系列分析
時系列分析とは、時間単位や日単位、月単位、年単位など、時間の経過に伴って変化する時系列データを用いて、未来の値がどのように変化するかを予測する分析手法です。商品の月別売上から来期の生産計画を作成する、Webサイトの曜日別アクセス数から翌月の需要予測を行うといったマーケティング分野のほか、株価や気象データ、人口統計など幅広い分野で活用されています。

ビジネスに役立つおすすめのアンケート調査
ビジネスで役立つアンケートについて代表的な調査を3つご紹介します。
企業の成長を促進するために、業界トレンドや新たなビジネスチャンスに関する情報をアンケートから得ることが出来ます。顧客の声に耳を傾けることが業績向上に寄与します。
企業の成長を促進するために、業界トレンドや新たなビジネスチャンスに関する情報をアンケートから得ることが出来ます。顧客の声に耳を傾けることが業績向上に寄与します。
1.顧客満足度調査
顧客満足度調査はお客様が商品やサービスを体験した後に、どれだけ満足しているのか数値化して調査する方法です。メリットは顧客にアンケートをとって感想を聞くことができるため、商品やサービスの品質において具体的な内容を把握できます。また、商品においてデータを数値化できるため、現状と今後の売上が伸びるのか分析するのに役立ちます。
2.新商品における受容把握調査
受容把握調査は新商品やサービスの改善をしたいときに、消費者にアンケートやインタビューをしてニーズを掴むことが可能です。メリットは、商品についての価値や抵抗感があるかなど、消費者のリアルな声を聞くことができます。また、消費者のニーズにマッチしているのか現状把握できるため、的確な部分を改善するのに役立ちます。
▼関連記事
コンセプト受容性調査とは?目的や実施方法、事例を詳しく解説
▼関連記事
コンセプト受容性調査とは?目的や実施方法、事例を詳しく解説
3.自社の商品やサービスの認知度調査
認知度調査は自社、または他社の競合との知名度やブランドについて把握することが可能です。メリットは、調査することで認知度を把握できるため、マーケティングや広告の戦略において的確な改善策を分析しやすくなり、製品の開発に役立てられます。また、認知度により市場における自社製品の占有率や立場も明確にできます。
▼関連記事
ブランド認知度調査とは?方法とポイント・注意点ついて解説
▼関連記事
ブランド認知度調査とは?方法とポイント・注意点ついて解説
まとめ
アンケートで得たデータは集計が必須になります。また、データへの理解を深めるためにクロス集計や分析を行い役立つデータにします。しかし、集計作業をExcelなどを使って自力ですると時間や労力もかかります。
ネットリサーチツール「Surveroid(サーベロイド)」は、アンケートシステム・消費者パネル・集計ツールの3点の提供をしているため、意思決定までの時間を縮めることができます。マーケティング施策を実行する上で市場調査をご自身で実施できますので、サービス詳細が気になる方はお気軽に資料をダウンロードください。
ネットリサーチツール「Surveroid(サーベロイド)」は、アンケートシステム・消費者パネル・集計ツールの3点の提供をしているため、意思決定までの時間を縮めることができます。マーケティング施策を実行する上で市場調査をご自身で実施できますので、サービス詳細が気になる方はお気軽に資料をダウンロードください。
 サーベロイドでリサーチをはじめませんか?
サーベロイドでリサーチをはじめませんか?80 件





