 お問い合わせ
お問い合わせ
 資料請求
資料請求
目次
決定木分析とは、データを条件分岐でグループ分けしながら「どんな人が買うのか」「何が満足度を左右するのか」といった要因を見つける分析手法です。結果が樹形図(ツリー)として出力されるため、数式が苦手でも直感的に理解しやすく、上司やチームへ説明しやすいのが特徴です。
本記事では、決定木分析の基本から、マーケティングでの活用シーン、結果の見方、実施手順、注意点までをわかりやすく解説します。分析結果を“見える化”して、ターゲット設計や施策の意思決定に役立てましょう。
本記事では、決定木分析の基本から、マーケティングでの活用シーン、結果の見方、実施手順、注意点までをわかりやすく解説します。分析結果を“見える化”して、ターゲット設計や施策の意思決定に役立てましょう。

決定木分析とは?
決定木分析とは、観測された変数(説明変数)の中から、目的変数(購入有無・満足/不満・継続/解約など)に影響する要因を明らかにし、樹木状のモデル(決定木)を作成する分析手法です。
例えば、購入率40%の商品が「誰によく買われているのか」を知りたいとき、(図:決定木の例)のように条件分岐をたどることで、購入率が高くなる条件の組み合わせを視覚的に把握できます。
決定木分析は、主にマーケティング施策やマーケティングリサーチで活用されることが多い一方、決定木は機械学習でも広く用いられており、ランダムフォレストや勾配ブースティング(XGBoostなど)といったアンサンブル学習の主要手法では、決定木が基本要素として利用されています。
例えば、購入率40%の商品が「誰によく買われているのか」を知りたいとき、(図:決定木の例)のように条件分岐をたどることで、購入率が高くなる条件の組み合わせを視覚的に把握できます。
決定木分析は、主にマーケティング施策やマーケティングリサーチで活用されることが多い一方、決定木は機械学習でも広く用いられており、ランダムフォレストや勾配ブースティング(XGBoostなど)といったアンサンブル学習の主要手法では、決定木が基本要素として利用されています。

決定木分析とは
決定木分析を活用する3つのメリット
データ分析には多種多様な手法が存在しますが、その中で決定木分析が多くのマーケターやデータアナリストに選ばれるのには明確な理由があります。特にビジネスの現場では、分析の正確さだけでなく、その結果を関係者に説明し納得してもらうプロセスが重要です。ここでは、決定木分析ならではの強みである3つのメリットについて詳しく見ていきます。
分析結果が視覚的で直感的に理解しやすい
決定木分析の最大のメリットは、分析結果が樹形図として可視化されることです。複雑な数式や統計用語を使わずに、分岐条件と結果の関係が一目でわかる図で表現されます。そのため、データ分析の専門知識を持たない経営層や他部署のメンバーに対しても、分析結果をスムーズに共有することができます。
例えば、「なぜこのターゲット層を選定したのか」という根拠を説明する際、「20代であり、かつ過去にWebサイトを3回以上訪問した層の購入率が最も高かったからです」というように、図を指し示しながら論理的に説明することが可能です。ブラックボックスになりがちなAIや高度な統計モデルとは異なり、結論に至るプロセスが透明であるため、施策への合意形成が得やすくなります。
例えば、「なぜこのターゲット層を選定したのか」という根拠を説明する際、「20代であり、かつ過去にWebサイトを3回以上訪問した層の購入率が最も高かったからです」というように、図を指し示しながら論理的に説明することが可能です。ブラックボックスになりがちなAIや高度な統計モデルとは異なり、結論に至るプロセスが透明であるため、施策への合意形成が得やすくなります。
データの欠損や異常値に対して柔軟に対応できる
一般的な統計解析手法の中には、データの一部が欠けていたり、極端に大きな値や小さな値が含まれていたりすると、分析結果が大きく歪んでしまうものがあります。しかし、決定木分析はデータのばらつきに対して比較的頑健な手法です。
データの前処理として、欠損値を厳密に埋めたり、異常値をすべて排除したりといった手間のかかる作業を完璧に行わなくても、分析を実行できるケースが多くあります。もちろんデータの質は重要ですが、ビジネスの現場にあるデータは必ずしも綺麗に整備されているとは限りません。ある程度のノイズが含まれている状態でも、有意なルールを見つけ出せる点は、実務において大きな利点となります。
データの前処理として、欠損値を厳密に埋めたり、異常値をすべて排除したりといった手間のかかる作業を完璧に行わなくても、分析を実行できるケースが多くあります。もちろんデータの質は重要ですが、ビジネスの現場にあるデータは必ずしも綺麗に整備されているとは限りません。ある程度のノイズが含まれている状態でも、有意なルールを見つけ出せる点は、実務において大きな利点となります。
重要な要因が何であるかを特定しやすい
決定木分析を行うと、データの上位に近い部分で分岐に使われた変数ほど、目的変数に対する影響力が強いと判断できます。つまり、ターゲットを分類したり数値を予測したりする上で、どの要因が最も重要なのかが優先順位付きで明らかになります。
マーケティング施策を考える際、あらゆる顧客属性を考慮しようとするとキリがありません。しかし、決定木分析を用いれば「性別よりも居住地の方が購入への影響度が大きい」といった知見が得られます。これにより、効果の低い要因にリソースを割くことを避け、最も成果に直結する重要な要因に絞って戦略を立てることが可能になります。
マーケティング施策を考える際、あらゆる顧客属性を考慮しようとするとキリがありません。しかし、決定木分析を用いれば「性別よりも居住地の方が購入への影響度が大きい」といった知見が得られます。これにより、効果の低い要因にリソースを割くことを避け、最も成果に直結する重要な要因に絞って戦略を立てることが可能になります。
決定木分析のデメリットと対策
多くのメリットを持つ決定木分析ですが、万能な手法というわけではありません。特性を理解せずに利用すると、誤った解釈をしてしまったり、期待した精度が出なかったりすることもあります。分析に取り掛かる前に、注意すべきポイントも把握しておきましょう。
データのわずかな変化で結果が大きく変わる可能性がある
決定木分析は、学習データに対して最適な分岐条件を探してモデルを作成します。そのため、元となるデータセットの内容が少し変わるだけで、選ばれる分岐条件やツリーの構造が大きく変化してしまうことがあります。これをモデルの不安定性と呼びます。
例えば、先月のデータで分析したときと今月のデータで分析したときで、全く異なる要因が重要であるという結果が出る可能性があります。
対策の考え方
・データ期間やサンプルを変えて、同じ傾向が再現されるか確認する
・深さを制限し、枝が増えすぎないようにする
・より安定させたい場合は、ランダムフォレストのように複数の決定木を統合する手法も検討する
単一の決定木の結果だけを鵜呑みにせず、変動があることを前提に解釈し、検証とセットで運用することが大切です。
例えば、先月のデータで分析したときと今月のデータで分析したときで、全く異なる要因が重要であるという結果が出る可能性があります。
対策の考え方
・データ期間やサンプルを変えて、同じ傾向が再現されるか確認する
・深さを制限し、枝が増えすぎないようにする
・より安定させたい場合は、ランダムフォレストのように複数の決定木を統合する手法も検討する
単一の決定木の結果だけを鵜呑みにせず、変動があることを前提に解釈し、検証とセットで運用することが大切です。
線形性のあるデータの予測には不向きな場合がある
決定木分析は、条件による区分けでデータを捉えるため、階段状の境界線で予測を行うことになります。そのため、変数同士が直線的な関係(比例関係など)にあるデータを表現するのは苦手としています。
例えば、「気温が上がれば上がるほど、アイスクリームの売上が一定の割合で伸びる」といった単純な線形関係がある場合、回帰分析のような手法の方が高い精度で予測できることがあります。
対策の考え方
・目的が“予測精度”か“説明しやすさ”かを先に決める
・線形関係が強そうなら回帰分析も候補に入れる
・決定木は「要因の当たりをつける」「セグメントを切る」用途で強い、と使い分ける
例えば、「気温が上がれば上がるほど、アイスクリームの売上が一定の割合で伸びる」といった単純な線形関係がある場合、回帰分析のような手法の方が高い精度で予測できることがあります。
対策の考え方
・目的が“予測精度”か“説明しやすさ”かを先に決める
・線形関係が強そうなら回帰分析も候補に入れる
・決定木は「要因の当たりをつける」「セグメントを切る」用途で強い、と使い分ける

決定木分析を行うための具体的な手順
決定木分析を進めるためには、正しいプロセスを踏むことが成功への近道です。ツールを使えば計算自体は自動で行われますが、どのようなデータを入力し、どのようにモデルを調整するかは人間の判断に委ねられています。ここでは、質の高い分析結果を得るための標準的なフローを解説します。
分析の目的とゴールを明確に設定する
最初に行うべきは、何のために分析を行うのかという目的の明確化です。単にデータを分類するだけではビジネス上の価値は生まれません。「優良顧客の共通点を見つけたい」「キャンペーンに反応しやすい層を抽出したい」「解約のリスク要因を特定したい」など、解決したい課題を具体的に言語化します。
目的が定まれば、それが「分類」の問題なのか「数値予測」の問題なのかが決まります。ゴール設定が曖昧なまま分析を始めると、不要なデータを集めてしまったり、解釈に困る結果が出たりするため、この工程は非常に重要です。
目的が定まれば、それが「分類」の問題なのか「数値予測」の問題なのかが決まります。ゴール設定が曖昧なまま分析を始めると、不要なデータを集めてしまったり、解釈に困る結果が出たりするため、この工程は非常に重要です。
目的変数を決定し必要なデータを収集・加工する
次に、分析の対象となる「目的変数」と、その予測に使えそうな「説明変数」を準備します。目的変数とは「商品の購入有無」や「契約継続期間」など、予測したい結果のことです。説明変数は「年齢」「性別」「利用頻度」などの要因となるデータです。
社内にあるCRMデータやWeb解析データ、アンケート結果などから必要な情報を集めます。この段階で、データ形式を統一したり、明らかに無関係な項目を除外したりする作業を行います。分析精度を高めるためには、目的変数に対して関連性が高いと思われるデータを漏れなく用意することがポイントです。
社内にあるCRMデータやWeb解析データ、アンケート結果などから必要な情報を集めます。この段階で、データ形式を統一したり、明らかに無関係な項目を除外したりする作業を行います。分析精度を高めるためには、目的変数に対して関連性が高いと思われるデータを漏れなく用意することがポイントです。
分岐の基準を設定してモデルを構築する
データの準備ができたら、決定木モデルを構築します。多くの場合は分析ツールやプログラミング言語のライブラリを使用します。ここでは、データをどの基準で分割するかというアルゴリズムを選択します。
代表的なアルゴリズムにはCARTやC4.5などがありますが、ツールによっては自動で最適なものを選択してくれる場合もあります。また、どの程度まで深く分岐させるか、一つのノードに最低何件のデータが必要かといったパラメータを設定します。最初はデフォルトの設定で試行し、結果を見ながら調整していくのが一般的です。
代表的なアルゴリズムにはCARTやC4.5などがありますが、ツールによっては自動で最適なものを選択してくれる場合もあります。また、どの程度まで深く分岐させるか、一つのノードに最低何件のデータが必要かといったパラメータを設定します。最初はデフォルトの設定で試行し、結果を見ながら調整していくのが一般的です。
モデルの精度を検証して剪定(枝刈り)を行う
モデルが完成したら、その精度を確認します。学習に使ったデータに対しては高い精度が出ても、未知のデータに対しては精度が落ちる「過学習(オーバーフィッティング)」が起きることがあります。木が複雑になりすぎると、特定のデータに特化しすぎて汎用性が失われるのです。
過学習を防ぐために行うのが「剪定(枝刈り)」という作業です。重要度の低い末端の枝を削除し、モデルをシンプルにすることで、未知のデータに対しても安定した予測ができるように調整します。精度の検証と剪定を繰り返し、実務で使えるレベルのモデルに仕上げていきます。
過学習を防ぐために行うのが「剪定(枝刈り)」という作業です。重要度の低い末端の枝を削除し、モデルをシンプルにすることで、未知のデータに対しても安定した予測ができるように調整します。精度の検証と剪定を繰り返し、実務で使えるレベルのモデルに仕上げていきます。
マーケティングリサーチでの利用シーン
マーケティングリサーチにおいて決定木分析は、アンケート結果や行動ログなどの膨大なデータから「消費者の本音」を導き出すために活用されます。統計的な裏付けを持ちながらも、分析結果が視覚的に理解しやすいため、調査結果を基にした社内合意が得やすいというメリットがあります。具体的な3つの利用シーンを通じて、リサーチの現場でどのように役立てられているかを確認していきましょう。
アンケートデータから導き出す顧客満足度の構造把握
顧客満足度(CS)調査において、どの要素が総合的な満足度に最も寄与しているかを探る際に決定木分析は非常に有効です。「接客」「価格」「品質」「店舗の清潔さ」といった複数の項目が、どのように組み合わさって満足・不満足の分岐を作っているかを明らかにします。
例えば、価格に不満があっても品質が一定水準を超えていれば総合満足度は高くなる、といった「条件の組み合わせ」による心理構造が可視化されます。これにより、単に平均点の低い項目を改善するのではなく、満足度を底上げするために最も影響力の強い項目から優先的に手を打つことが可能になります。
例えば、価格に不満があっても品質が一定水準を超えていれば総合満足度は高くなる、といった「条件の組み合わせ」による心理構造が可視化されます。これにより、単に平均点の低い項目を改善するのではなく、満足度を底上げするために最も影響力の強い項目から優先的に手を打つことが可能になります。
ターゲット層のライフスタイルに応じたセグメンテーション
消費者のライフスタイルや価値観が多様化する中で、単純な人口統計学的属性(性別や年齢など)だけでは捉えきれない層を分類するためにも活用されます。趣味嗜好や休日の過ごし方といったリサーチデータを分析し、類似した行動パターンを持つグループを抽出します。
特定の価値観を持つ層がどのようなメディアを好み、どのようなタイミングで購買意欲が高まるのかを木構造で紐解くことで、より解像度の高いペルソナ像を構築できます。この分析結果は、クリエイティブ制作やメディアプランニングの指針として、リサーチ部門からマーケティング部門へ橋渡しをする際の強力な根拠となります。
特定の価値観を持つ層がどのようなメディアを好み、どのようなタイミングで購買意欲が高まるのかを木構造で紐解くことで、より解像度の高いペルソナ像を構築できます。この分析結果は、クリエイティブ制作やメディアプランニングの指針として、リサーチ部門からマーケティング部門へ橋渡しをする際の強力な根拠となります。
コンセプトテストにおける受容性の分岐点調査
新商品の開発段階で行われるコンセプトテストにおいて、どのようなベネフィットが購入意向を高めるのかを特定するために決定木分析が用いられます。提示した複数のコンセプト案に対して、「誰が」「どの要素に」反応したのかを詳細に分析します。
特定の層には「時短」という訴求が刺さる一方で、別の層には「家族の健康」が購入の決定打になるといった分岐が明確になります。市場全体の平均値では見落とされがちなニッチな需要や、ターゲットごとの最適な訴求ポイントを絞り込めるため、ローンチ後のミスマッチを防ぐ精度の高いマーケティング戦略が策定できます。
特定の層には「時短」という訴求が刺さる一方で、別の層には「家族の健康」が購入の決定打になるといった分岐が明確になります。市場全体の平均値では見落とされがちなニッチな需要や、ターゲットごとの最適な訴求ポイントを絞り込めるため、ローンチ後のミスマッチを防ぐ精度の高いマーケティング戦略が策定できます。
-
1万円からWebアンケート調査できるサービス内容を確認する
-
初期費用や月額費一切なしコストを抑えてリサーチをする
データサイエンスでの利用シーン
データサイエンスの領域において、決定木分析は「説明可能なAI(XAI)」の先駆けとして非常に重要な役割を担っています。高度な機械学習モデルはブラックボックス化しやすい傾向にありますが、決定木は予測の根拠を明確なルールとして抽出できるため、データから法則性を見出す際に多用されます。ここでは、データサイエンティストが直面する具体的な課題解決において、決定木がどのように活用されているかを詳しく解説します。
予測モデル構築における重要な特徴量の選定
膨大な変数の中から予測に本当に寄与する要素を絞り込む「特徴量選択」は、データサイエンスの工程で極めて重要です。決定木分析を用いると、どの変数が最も効率的にデータを分割できたかが数値化されるため、影響力の強い項目を客観的に選別できます。
不要なデータを除外してモデルを簡略化することで、計算コストを抑えるだけでなく、未知のデータに対する予測精度を高めることが可能になります。特に、変数が数百を超えるような大規模なデータセットを扱う際に、分析の優先順位をつけるための最初のステップとして頻繁に活用されています。
不要なデータを除外してモデルを簡略化することで、計算コストを抑えるだけでなく、未知のデータに対する予測精度を高めることが可能になります。特に、変数が数百を超えるような大規模なデータセットを扱う際に、分析の優先順位をつけるための最初のステップとして頻繁に活用されています。
金融・医療分野での不正・リスク検知への応用
高い透明性と説明責任が求められる金融や医療の現場では、決定木分析の「判断基準の明確さ」が大きな強みとなります。例えば、クレジットカードの不正利用検知や病気の診断支援において、なぜそのデータが「リスクあり」と判定されたのかを論理的に説明できるからです。
「過去に同様の取引があるか」「特定の時間帯の操作か」といった条件分岐がツリー形式で示されるため、現場の専門家が分析結果を納得感を持って受け入れられます。ディープラーニングのような複雑な手法を導入する前のベースラインモデルとして、あるいは最終的な意思決定の根拠を示すためのツールとして、信頼性の高いシステム構築に寄与しています。
「過去に同様の取引があるか」「特定の時間帯の操作か」といった条件分岐がツリー形式で示されるため、現場の専門家が分析結果を納得感を持って受け入れられます。ディープラーニングのような複雑な手法を導入する前のベースラインモデルとして、あるいは最終的な意思決定の根拠を示すためのツールとして、信頼性の高いシステム構築に寄与しています。
ランダムフォレストや勾配ブースティングへの発展
決定木単体での分析にとどまらず、複数の決定木を組み合わせる「アンサンブル学習」の基礎パーツとしてもデータサイエンスを支えています。一つの木では学習データの癖に影響されすぎる「過学習」が起きやすいですが、何百もの木を統合することで、より堅牢で強力な予測モデルへと進化します。
現在、多くのデータコンペティションやビジネスの現場で主流となっている「ランダムフォレスト」や「XGBoost」といった手法は、すべてこの決定木の仕組みを応用したものです。単一のモデルで構造を理解した上で、これら高度なアルゴリズムへ展開していくことが、データサイエンスにおける定石となっています。
現在、多くのデータコンペティションやビジネスの現場で主流となっている「ランダムフォレスト」や「XGBoost」といった手法は、すべてこの決定木の仕組みを応用したものです。単一のモデルで構造を理解した上で、これら高度なアルゴリズムへ展開していくことが、データサイエンスにおける定石となっています。

分析結果の見方
決定木分析は“図が出て終わり”ではなく、木構造を正しく読み解くことが重要です。どの要素が結果に影響しているか、どのセグメントで数値が伸びているかを確認していきましょう。
①上から順に説明変数を確認する(上位ほど重要になりやすい)

確認点
まずは、ツリーの上(根)から順に、どの説明変数が使われているかを確認します。
一般に、上位に登場する変数ほど、目的変数(購入率など)を分ける力が強いと解釈されます。
(例)上位に「世帯年収」がある場合
→ 世帯年収が購入有無の分岐に強く関係している可能性があります。
そのうえで、次の分岐として「性年代」が登場する場合
→ 世帯年収で大きく分けた後、性年代がさらに購入有無の差を生んでいる、という読み方になります。
※ただし、後述する通り、剪定やツールの設定(深さ、最小サンプル数など)によって、出てくる変数は変わることがあります。
一般に、上位に登場する変数ほど、目的変数(購入率など)を分ける力が強いと解釈されます。
(例)上位に「世帯年収」がある場合
→ 世帯年収が購入有無の分岐に強く関係している可能性があります。
そのうえで、次の分岐として「性年代」が登場する場合
→ 世帯年収で大きく分けた後、性年代がさらに購入有無の差を生んでいる、という読み方になります。
※ただし、後述する通り、剪定やツールの設定(深さ、最小サンプル数など)によって、出てくる変数は変わることがあります。
②人数(n)と結果の値(購入率など)をセットで確認する

確認点
次に、各ノード(枝の先)に表示される 人数(n) と 結果の値(購入率、満足率、解約率など) を確認します。
ここは実務上とても大事で、「数値が高い」だけでなく「nが小さすぎない」 セグメントを狙うのが基本です。
(例)n=1,000のデータで全体の購入率が23%のとき
世帯年収600万円以上の購入率が34%
→ 600万円未満より高く、購入に関係している可能性がある
さらに性年代で分けた結果、20〜30代男性と20代女性の購入率が53%
→ 「世帯年収600万円以上 × 20〜30代(男女)」の条件で購入率が上がっている
このように、数値が上がる分岐点を見つけ、その条件の組み合わせをターゲット候補として整理すると、施策に落とし込みやすくなります。
(ポイント)購入率が高くてもnが極端に小さい場合は、再現性や施策効率の面で注意が必要です。まずは“候補”として扱い、クロス集計や追加検証で確かめると安心です。
ここは実務上とても大事で、「数値が高い」だけでなく「nが小さすぎない」 セグメントを狙うのが基本です。
(例)n=1,000のデータで全体の購入率が23%のとき
世帯年収600万円以上の購入率が34%
→ 600万円未満より高く、購入に関係している可能性がある
さらに性年代で分けた結果、20〜30代男性と20代女性の購入率が53%
→ 「世帯年収600万円以上 × 20〜30代(男女)」の条件で購入率が上がっている
このように、数値が上がる分岐点を見つけ、その条件の組み合わせをターゲット候補として整理すると、施策に落とし込みやすくなります。
(ポイント)購入率が高くてもnが極端に小さい場合は、再現性や施策効率の面で注意が必要です。まずは“候補”として扱い、クロス集計や追加検証で確かめると安心です。
決定木分析の注意点
決定木分析は視覚的に理解しやすい反面、アウトプットの解釈や精度維持において意識すべきポイントがあります。木が複雑になりすぎたり、ツール側の設定で見えるものが変わったりするため、以下の注意点を押さえておきましょう。
①ツリーに現れていない変数は「効いていない」とは限らない(剪定・設定の影響)
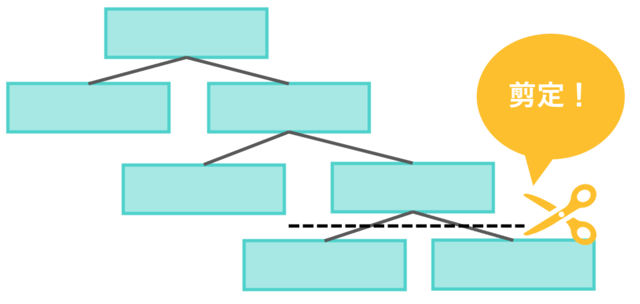
剪定イメージ図
ツリーに現れていない変数は、必ずしも「影響がない」とは言い切れません。
モデルをシンプルにするために 剪定(枝刈り) が行われると、影響が小さい枝や説明が複雑になる枝は表示されないことがあります。また、ツール設定(木の深さ、最小サンプル数など)によって、そもそも採用される分岐が変わる場合もあります。
「出ていない=不要」と即断せず、目的に照らして必要なら再分析や別手法で確認するのが安全です。
モデルをシンプルにするために 剪定(枝刈り) が行われると、影響が小さい枝や説明が複雑になる枝は表示されないことがあります。また、ツール設定(木の深さ、最小サンプル数など)によって、そもそも採用される分岐が変わる場合もあります。
「出ていない=不要」と即断せず、目的に照らして必要なら再分析や別手法で確認するのが安全です。
②木の構造が深すぎると解釈が難しく、過学習の原因にもなる
剪定をする理由として、木の構造が深すぎる(分類しすぎる)と解釈が難しくなること、そして今のデータにフィットしすぎる(過学習)と未知データで精度が落ちやすいことが挙げられます。
実務では「説明しやすさ」と「精度」のバランスが重要です。枝が増えすぎたら、深さ制限や最小サンプル数の設定、剪定などでシンプルにし、安定して使える形に整えましょう。
実務では「説明しやすさ」と「精度」のバランスが重要です。枝が増えすぎたら、深さ制限や最小サンプル数の設定、剪定などでシンプルにし、安定して使える形に整えましょう。
用語の説明
結果を見るだけなら、すべてを暗記する必要はありません。ツール利用時によく出てくる言葉だけ押さえましょう。
・分類木/回帰木:目的変数がカテゴリ(購入有無など)なら分類木、数値(売上など)なら回帰木
・アルゴリズム:CART、CHAID、C4.5など(ツールが採用している方式の名称)
・分割の基準:ジニ係数、エントロピー(平均情報量)など(“うまく分かれる分け方”を評価する指標)
・剪定(枝刈り):枝を減らして、過学習を抑え、解釈しやすくする調整
・分類木/回帰木:目的変数がカテゴリ(購入有無など)なら分類木、数値(売上など)なら回帰木
・アルゴリズム:CART、CHAID、C4.5など(ツールが採用している方式の名称)
・分割の基準:ジニ係数、エントロピー(平均情報量)など(“うまく分かれる分け方”を評価する指標)
・剪定(枝刈り):枝を減らして、過学習を抑え、解釈しやすくする調整
まとめ
決定木分析は、データを条件分岐で整理しながら「どの要因が結果に効いているか」「どの条件の組み合わせで数値が上がるか」を可視化できる分析手法です。
特にマーケティングでは、ターゲットの絞り込みや訴求軸の発見、満足度の構造把握などに活用しやすく、分析結果を図として共有できる点も大きなメリットです。
ただし、データや設定のわずかな違いで構造が変わることがあるため、n(人数)と数値をセットで確認し、必要に応じてクロス集計や追加検証を行いながら、施策に落とし込むのがおすすめです。
特にマーケティングでは、ターゲットの絞り込みや訴求軸の発見、満足度の構造把握などに活用しやすく、分析結果を図として共有できる点も大きなメリットです。
ただし、データや設定のわずかな違いで構造が変わることがあるため、n(人数)と数値をセットで確認し、必要に応じてクロス集計や追加検証を行いながら、施策に落とし込むのがおすすめです。
セルフ型ネットリサーチツールのご案内
決定木分析は、購入意向や満足度などの「目的変数」と、属性・行動・意識などの「説明変数」が揃うほど、打ち手に直結する示唆が得やすくなります。
「Surveroid(サーベロイド)」なら、アンケート調査からインタビュー調査まで1つのツールで完結でき、『アンケートの作成~配信~回収~集計』をご自身でスピーディーに実施できます。市場調査や新商品のニーズ把握など、定量と定性の両面から調査が可能です。ご興味のある方はぜひお問い合わせください。
「Surveroid(サーベロイド)」なら、アンケート調査からインタビュー調査まで1つのツールで完結でき、『アンケートの作成~配信~回収~集計』をご自身でスピーディーに実施できます。市場調査や新商品のニーズ把握など、定量と定性の両面から調査が可能です。ご興味のある方はぜひお問い合わせください。
 サーベロイドでリサーチをはじめませんか?
サーベロイドでリサーチをはじめませんか?70 件





