 お問い合わせ
お問い合わせ
 資料請求
資料請求

アンケートの分析の際、回答データだけでなくパラデータを使って分析したいということがあります。
パラデータというのは、回答に要した時間、回答に使った機器(パソコンか、スマートフォンか等)などのように、「調査データを取得するプロセスのデータ」のことをいいます。欧米の研究者の中では、特に調査・分析手法研究の観点からパラデータの利用が盛んになっているようです。(cf.『社会と調査 第18号 特集 パラデータの活用に向けて』 2017 社会調査協会)
パラデータの分析については次回以降にご紹介したいと思いますが、パラデータを扱うときは、まずその前処理、分析に適した変数に変換するのに手間がかかることが多いです。
そこで、今回はRを使ったパラデータの前処理の一例をご紹介します。
使用したデータの形式は、マーケティングアプリケーションズ社のMApps forSurveyで取得したweb調査のパラデータ形式です。(セルフリサーチ用のSurveroidとは異なる、リサーチ会社向けのアンケートツールです)
パラデータというのは、回答に要した時間、回答に使った機器(パソコンか、スマートフォンか等)などのように、「調査データを取得するプロセスのデータ」のことをいいます。欧米の研究者の中では、特に調査・分析手法研究の観点からパラデータの利用が盛んになっているようです。(cf.『社会と調査 第18号 特集 パラデータの活用に向けて』 2017 社会調査協会)
パラデータの分析については次回以降にご紹介したいと思いますが、パラデータを扱うときは、まずその前処理、分析に適した変数に変換するのに手間がかかることが多いです。
そこで、今回はRを使ったパラデータの前処理の一例をご紹介します。
使用したデータの形式は、マーケティングアプリケーションズ社のMApps forSurveyで取得したweb調査のパラデータ形式です。(セルフリサーチ用のSurveroidとは異なる、リサーチ会社向けのアンケートツールです)

パラデータ
上手は取得したパラデータです。それぞれ変数の内容は、以下のとおりです。
MID=回答者ID
START=回答を開始した日時
END=回答を完了した日時
TIME=回答に要した時間
UserAgent=回答に使われたデバイス(ブラウザ)のユーザーエージェント
IPAddress=回答者がアクセスしてきたipアドレス
まず、データをRに読み込んだうえで、START、ENDはキャラクターデータ、つまり単なる文字列なので、これを日時として扱えるように、strptime関数を使ってデータ変換します。
(R script)
library(dplyr)
df$START<-strptime(df$START,format="%Y/%m/%d-%H:%M:%S")
df$END<-strptime(df$END,format="%Y/%m/%d-%H:%M:%S")
分析上は、開始日時そのものというより、初期回答者か後期回答者かで回答に差異があるか、等を調べたいので、STARTの一番早い人を0とし、そのあとは開始日時の差を秒で表すstart_timeという変数を作ることにします。また、start_timeで回答者を10分位し、コードを振ります(変数名 st_quantile)。1が最初期回答者、10が最末期回答者になります。
このほかに、昼間回答者/夜間回答者、とか、平日回答者/土日回答者などといった変数もSTARTやENDの日時情報から作成して使えそうです。
また、回答に要した時間(TIME)は秒単位を変換します。TIMEから作ってもいいのですが、STARTとENDの差を取った方が簡単なので、それを上書きします。
(R script)
df$start_time<-as.numeric(df$START-min(df$START),units="secs")
df<-df%>%mutate(st_quantile = ntile(start_time, 10))
df$TIME<-as.numeric(df$END-df$START,units="secs")
これで、以下のようなデータに変換、追加されました。
MID=回答者ID
START=回答を開始した日時
END=回答を完了した日時
TIME=回答に要した時間
UserAgent=回答に使われたデバイス(ブラウザ)のユーザーエージェント
IPAddress=回答者がアクセスしてきたipアドレス
まず、データをRに読み込んだうえで、START、ENDはキャラクターデータ、つまり単なる文字列なので、これを日時として扱えるように、strptime関数を使ってデータ変換します。
(R script)
library(dplyr)
df$START<-strptime(df$START,format="%Y/%m/%d-%H:%M:%S")
df$END<-strptime(df$END,format="%Y/%m/%d-%H:%M:%S")
分析上は、開始日時そのものというより、初期回答者か後期回答者かで回答に差異があるか、等を調べたいので、STARTの一番早い人を0とし、そのあとは開始日時の差を秒で表すstart_timeという変数を作ることにします。また、start_timeで回答者を10分位し、コードを振ります(変数名 st_quantile)。1が最初期回答者、10が最末期回答者になります。
このほかに、昼間回答者/夜間回答者、とか、平日回答者/土日回答者などといった変数もSTARTやENDの日時情報から作成して使えそうです。
また、回答に要した時間(TIME)は秒単位を変換します。TIMEから作ってもいいのですが、STARTとENDの差を取った方が簡単なので、それを上書きします。
(R script)
df$start_time<-as.numeric(df$START-min(df$START),units="secs")
df<-df%>%mutate(st_quantile = ntile(start_time, 10))
df$TIME<-as.numeric(df$END-df$START,units="secs")
これで、以下のようなデータに変換、追加されました。
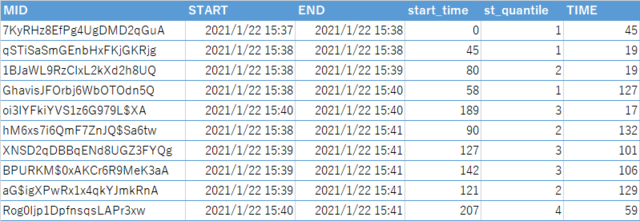
変換された回答時刻、時間データ
ユーザーエージェントは、uaparserjsというライブラリーを使って、簡単にブラウザやデバイスのファミリーを取得することができます。
(R script)
library(uaparserjs)
df<-df%>%mutate(ua_parse(UserAgent))
次のようなデータが追加できました。ここに示したのはアプリ(ブラウザ)、OS、機器のファミリー(大分類)情報ですが、バージョンなどの情報も追加できます。
(R script)
library(uaparserjs)
df<-df%>%mutate(ua_parse(UserAgent))
次のようなデータが追加できました。ここに示したのはアプリ(ブラウザ)、OS、機器のファミリー(大分類)情報ですが、バージョンなどの情報も追加できます。

ユーザーエージェントから得られたアプリ、OS、デバイスファミリー情報
最後に、IPアドレスについても処理してみます。
ドメイン情報を一つ一つ参照しに行くので、サンプルサイズが大きいと時間がかかることもありますが、iptoolsというライブラリでドメイン名に変換することができます。(ip_to_hostnameという関数はリスト形式で結果を返すため、データフレームに直してからデータに追加しています)
(R script)
library(iptools)
host<-ip_to_hostname(df$IPAddress)
host<-as.data.frame(do.call(rbind,host))
colnames(host)<-"hostname"
df<-cbind(df,host)
下図のhostname変数がipアドレスから取得したドメイン名のデータです。参照できなかったものは数値のipアドレスがそのまま格納されています。
もうひと手間かけて、後の方の親ドメイン名だけに変換したいところですが、これは少し工夫が必要そうですね。
ドメイン情報を一つ一つ参照しに行くので、サンプルサイズが大きいと時間がかかることもありますが、iptoolsというライブラリでドメイン名に変換することができます。(ip_to_hostnameという関数はリスト形式で結果を返すため、データフレームに直してからデータに追加しています)
(R script)
library(iptools)
host<-ip_to_hostname(df$IPAddress)
host<-as.data.frame(do.call(rbind,host))
colnames(host)<-"hostname"
df<-cbind(df,host)
下図のhostname変数がipアドレスから取得したドメイン名のデータです。参照できなかったものは数値のipアドレスがそのまま格納されています。
もうひと手間かけて、後の方の親ドメイン名だけに変換したいところですが、これは少し工夫が必要そうですね。

ipアドレスからホスト名への変換
アンケートのパラデータの前処理について、Rを使って簡単に済ませる方法を、少しだけご紹介しました。
▲
▲
10 件





